Il filesystem Linux spiegato semplice: cartelle, file, directory e mount
Guida semplice al filesystem Linux: scopri cosa sono la directory root /, /home, /etc, /usr, /var, /tmp, /dev, /proc, /boot e cosa significa montare un disco.
Capire il filesystem Linux è uno dei passaggi più importanti per iniziare a
orientarsi davvero dentro un sistema Linux. Molti utenti partono dai comandi,
dal terminale o dall’installazione di una distribuzione, ma poi si trovano
davanti a directory come /home, /etc, /usr, /var, /dev, /proc e
/boot senza avere una mappa chiara.
Su Windows siamo abituati a ragionare in modo diverso. C’è il disco C:, ci
può essere il disco D:, ci sono cartelle come Programmi, Utenti, Documenti,
Download e Desktop. In Linux, invece, tutto parte da una sola radice, indicata
con /, e da lì si sviluppa una struttura ad albero.
All’inizio questa organizzazione può sembrare strana. In realtà, Linux non mette i file a caso. Li organizza secondo una logica precisa: file utente da una parte, configurazioni da un’altra, programmi in altre directory, log in un’area dedicata, dispositivi rappresentati come file speciali e informazioni interne del sistema esposte attraverso filesystem virtuali.
L’obiettivo di questa guida è spiegare il filesystem Linux in modo semplice, senza partire subito da comandi complessi. L’idea è costruire una mappa mentale chiara: capire dove stanno file, programmi, configurazioni, log e dispositivi, e perché Linux li organizza in questo modo.
Perché il filesystem Linux è fondamentale
Il filesystem è il modo in cui un sistema operativo organizza, salva e ritrova le informazioni. Ogni volta che salviamo un documento, installiamo un programma, modifichiamo una configurazione, leggiamo un log o colleghiamo una chiavetta USB, il sistema deve sapere dove mettere quei dati e come recuperarli.
In Linux il filesystem non è solo un insieme di cartelle. È una parte centrale del sistema operativo. Attraverso il filesystem passano file personali, programmi, librerie, configurazioni, log, dispositivi, processi e informazioni interne del kernel.
Nel primo episodio della serie abbiamo visto l’architettura generale di Linux: hardware, kernel, shell, librerie, utility, applicazioni, user space, kernel space e system call. Il filesystem si collega direttamente a questi concetti.
Quando un programma vuole aprire o salvare un file, non accede direttamente al disco. Il programma effettua una richiesta al sistema operativo. Il kernel controlla se il file esiste, se l’utente ha i permessi necessari, dove si trova fisicamente il dato e quale dispositivo deve essere usato.
Questo significa che il filesystem è uno dei punti in cui si incontrano molti elementi fondamentali di Linux: kernel, applicazioni, permessi, dispositivi, system call e spazio utente.
Capire il filesystem non serve solo a “sapere dove sono le cartelle”. Serve a capire come Linux organizza il sistema.
Cosa significa “tutto è un file” in Linux
Una delle frasi più famose del mondo Linux è: “tutto è un file”.
Detta così può sembrare una frase esagerata. Non significa che ogni cosa in Linux sia davvero un documento di testo salvato su disco. Il significato è più profondo: Linux rappresenta molte risorse del sistema attraverso un’interfaccia simile a quella dei file.
Un file normale può essere aperto, letto, scritto e chiuso. Linux usa questa idea anche per molte altre risorse. Non solo documenti, immagini o script, ma anche directory, dispositivi, terminali, dischi, processi e informazioni del kernel.
Per esempio, un file di testo è un file normale. Una directory è un tipo
speciale di file che contiene riferimenti ad altri file e directory. Un disco
può essere rappresentato da un file speciale dentro /dev, come /dev/sda o
/dev/nvme0n1. Un terminale può essere rappresentato da un file speciale come
/dev/tty. Un processo può avere informazioni disponibili dentro /proc.
Quindi, quando diciamo che in Linux “tutto è un file”, dobbiamo intenderlo come un’astrazione. Linux usa il concetto di file come modello comune per rappresentare molte parti del sistema.
Questa idea rende Linux molto coerente. Se molte risorse possono essere rappresentate come file, allora strumenti semplici possono diventare molto potenti.
Non tutti i file sono uguali
Un errore comune è pensare che tutto ciò che vediamo nel filesystem sia un file normale. Non è così.
Nel filesystem Linux possiamo incontrare diversi tipi di elementi.
I file normali sono quelli più familiari: documenti, immagini, file audio, video, script, archivi compressi, file di configurazione e codice sorgente.
Le directory sono contenitori di file e altre directory. Nel linguaggio quotidiano vengono spesso chiamate cartelle, ma tecnicamente sono strutture che organizzano riferimenti ad altri elementi del filesystem.
I file dispositivo sono file speciali che rappresentano dispositivi
hardware o risorse gestite dal kernel. Si trovano soprattutto dentro /dev.
Non sono file da aprire o modificare come se fossero documenti. Sono punti di
accesso verso dispositivi.
I file virtuali o pseudo-file sono ancora diversi. In directory come
/proc, molti file non sono realmente salvati su disco. Vengono generati
dinamicamente dal kernel per mostrare informazioni sul sistema, sui processi,
sulla memoria, sulla CPU o su altri aspetti interni.
Questa distinzione è importante. In Linux il filesystem non mostra solo “cose salvate sul disco”. Mostra anche accessi a dispositivi, viste dinamiche del sistema e punti di controllo.
Il filesystem come mappa del sistema
Possiamo immaginare il filesystem Linux come una grande mappa.
Su questa mappa non troviamo soltanto documenti e cartelle personali. Troviamo anche aree amministrative, archivi, registri, pannelli tecnici, accessi ai dispositivi e finestre da cui osservare cosa sta succedendo nel sistema.
Questa immagine è utile soprattutto per capire directory come /dev e /proc.
Dentro /dev non troviamo documenti personali, ma rappresentazioni di
dispositivi. Dentro /proc non troviamo normali file salvati su disco, ma
informazioni dinamiche generate dal kernel.
Il filesystem Linux quindi è più di una struttura di archiviazione. È anche un modo per esporre e organizzare molte risorse del sistema operativo.
Quando capiamo questa idea, Linux diventa molto meno misterioso.
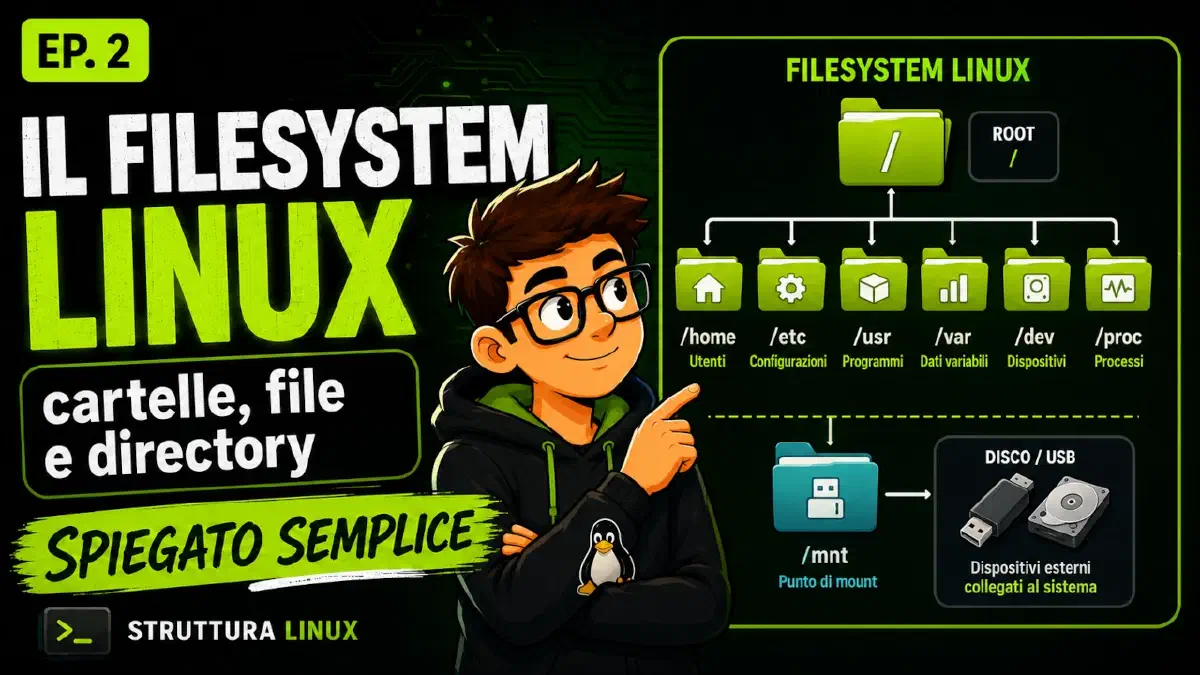
La directory root /: il punto di partenza di tutto
Il centro del filesystem Linux è la directory root, indicata con /.
Attenzione però a non confondere due concetti diversi. In Linux la parola
“root” può indicare l’utente amministratore, cioè l’utente con i massimi
privilegi. Ma la directory /, chiamata root directory, è un’altra cosa: è la
radice del filesystem.
Tutto parte da /.
A differenza di Windows, Linux non organizza lo spazio partendo da lettere di
unità come C:, D: o E:. In Linux esiste un unico grande albero che parte
da /.
Da questa radice partono le directory principali: /home, /etc, /bin,
/usr, /var, /tmp, /dev, /proc, /boot e molte altre.
L’analogia più semplice è quella di un albero. La radice è /. Da lì partono i
rami principali. Da questi rami partono altri rami. Ogni file ha un percorso
preciso dentro questa struttura.
Per esempio, un documento può trovarsi in:
/home/mario/documenti/appunti.txt
Un programma può trovarsi in:
/usr/bin
Un file di configurazione può stare in:
/etc
Un log può trovarsi in:
/var/log
Questa struttura ad albero è uno dei concetti fondamentali da capire. In Linux non si pensa prima al disco fisico. Si pensa prima al percorso dentro l’albero.
Mappa generale delle directory Linux principali
Per iniziare non serve conoscere tutte le directory esistenti in Linux. È molto più utile capire il ruolo delle directory principali.
Ecco una mappa sintetica:
| Directory | Funzione principale |
|---|---|
/ |
radice del filesystem |
/home |
file personali degli utenti |
/etc |
configurazioni di sistema |
/bin |
comandi essenziali |
/usr |
programmi, librerie e file condivisi |
/var |
dati variabili, log, cache e dati dei servizi |
/tmp |
file temporanei |
/dev |
dispositivi rappresentati come file |
/proc |
informazioni dinamiche su processi e kernel |
/boot |
file necessari all’avvio del sistema |
Questa tabella è la prima vera mappa mentale del filesystem Linux.
Se cerchi i file personali, pensi a /home.
Se cerchi configurazioni di sistema, pensi a /etc.
Se cerchi programmi e comandi, pensi a /bin e /usr.
Se cerchi log, pensi a /var/log.
Se cerchi dispositivi, pensi a /dev.
Se vuoi osservare informazioni interne su processi e kernel, pensi a /proc.
Se vuoi capire cosa serve all’avvio del sistema, pensi a /boot.
/home: la casa degli utenti
La directory /home è probabilmente la più facile da capire per chi arriva da
altri sistemi operativi.
Dentro /home si trovano di solito le cartelle personali degli utenti. Se sul
sistema esiste un utente chiamato mario, la sua home sarà probabilmente:
/home/mario
Se esiste un utente chiamato giulia, la sua home sarà:
/home/giulia
Qui troviamo documenti, download, immagini, video, file di lavoro, configurazioni personali e dati specifici dell’utente.
Possiamo immaginare /home come la zona residenziale del sistema. Ogni utente
ha il proprio spazio.
Questa separazione è importante perché Linux è progettato come sistema multiutente. Più utenti possono usare lo stesso sistema, ognuno con i propri file, le proprie impostazioni e i propri permessi.
Un errore comune dei principianti è salvare file personali dentro directory di sistema. In generale, se stiamo lavorando sui nostri documenti, il posto naturale è la nostra home.
/etc: le configurazioni di sistema
La directory /etc contiene moltissimi file di configurazione.
Qui troviamo impostazioni di sistema, configurazioni di servizi, configurazioni di rete e file che indicano al sistema come comportarsi.
Se /home è la zona residenziale, /etc è l’ufficio amministrativo.
Non contiene normalmente documenti personali e non contiene i programmi principali. Contiene regole, impostazioni e istruzioni.
Per esempio, un servizio installato sul sistema può avere un file di
configurazione dentro /etc. Modificando quel file, possiamo cambiare il
comportamento del servizio.
Questa directory è molto importante, ma va trattata con attenzione. Modificare
file dentro /etc senza sapere cosa si sta facendo può causare problemi. Non
perché Linux sia fragile, ma perché lì si trovano configurazioni che possono
influenzare tutto il sistema.
La regola semplice è questa: quando vogliamo capire come è configurato qualcosa
a livello di sistema, spesso dobbiamo guardare in /etc. Ma prima di cambiare
un file è bene capire il suo ruolo e, quando opportuno, fare una copia di
backup.
/bin e /usr: programmi, comandi e librerie
In Linux i programmi eseguibili possono trovarsi in diverse directory. Due
nomi importanti sono /bin e /usr.
Storicamente /bin contiene comandi essenziali, cioè programmi fondamentali
per usare e amministrare il sistema. Sono strumenti di base che possono servire
anche in situazioni minime o di ripristino.
La directory /usr, invece, contiene moltissimi programmi, librerie e file
condivisi usati dal sistema e dagli utenti. Dentro /usr/bin, per esempio,
troviamo molti comandi e applicazioni installate.
Qui emerge una differenza importante rispetto a Windows. In Windows spesso un programma viene installato dentro una singola cartella, per esempio sotto “Programmi”. In Linux, invece, i componenti di un software possono essere distribuiti in più punti coerenti del filesystem.
Gli eseguibili possono stare in una directory, le librerie in un’altra, le
configurazioni in /etc, i log in /var/log, i dati variabili in /var.
All’inizio questo può sembrare più complicato. In realtà segue una logica ordinata: ogni tipo di file va nella zona corretta.
Linux organizza i file più per funzione che per singola applicazione vista dall’utente.
/var: dati variabili e log
La directory /var contiene dati variabili, cioè dati che cambiano durante il
funzionamento del sistema.
Uno degli esempi più importanti è:
/var/log
Dentro /var/log troviamo molti log del sistema e dei servizi.
I log sono registrazioni di eventi: errori, avvisi, attività dei servizi, messaggi del sistema, tentativi di accesso, problemi di configurazione e molte altre informazioni.
Quando qualcosa non funziona in Linux, spesso la soluzione non è reinstallare tutto. Il primo passo corretto è leggere i log.
Dentro /var possono trovarsi anche cache, spool, dati di servizi, file
temporanei persistenti, database locali di alcune applicazioni e contenuti
usati da server.
Una distinzione molto utile è questa:
/etc → come dovrebbe funzionare il sistema
/var → cosa succede mentre il sistema funziona
/etc contiene spesso regole e configurazioni. /var, e in particolare
/var/log, contiene spesso le tracce dell’attività.
Questa distinzione diventa molto importante quando si inizia a fare troubleshooting, cioè quando si cerca di capire perché qualcosa non funziona.
/tmp: file temporanei
La directory /tmp serve per file temporanei.
Programmi e utenti possono usarla per salvare dati provvisori che non devono necessariamente rimanere per sempre.
Possiamo immaginarla come un tavolo di lavoro condiviso. Ci appoggiamo qualcosa mentre lavoriamo, ma non è il posto giusto in cui conservare documenti importanti.
Un errore comune è pensare: “metto questo file in /tmp, poi lo riprendo
domani”. Meglio evitarlo. A seconda della distribuzione e della configurazione,
i file temporanei possono essere cancellati automaticamente.
La regola è semplice: /tmp va bene per appoggi temporanei, non per archiviare
dati importanti.
/dev: dispositivi rappresentati come file
La directory /dev è una delle più interessanti per capire la logica di Linux.
Dentro /dev troviamo file speciali che rappresentano dispositivi.
Un disco può apparire come:
/dev/sda
Una partizione può apparire come:
/dev/sda1
Un disco NVMe può apparire come:
/dev/nvme0n1
Un terminale può apparire come:
/dev/tty
Questi non sono file normali. Sono interfacce verso dispositivi gestiti dal kernel.
Qui si collega molto bene il discorso sull’architettura Linux. Le applicazioni
non parlano direttamente con l’hardware. Passano attraverso il kernel, i driver
e le system call. /dev è uno dei punti in cui questa idea diventa visibile
nel filesystem.
Quando vediamo /dev, dobbiamo pensare: qui non sto guardando documenti, sto
guardando accessi tecnici a dispositivi.
Proprio per questo bisogna fare attenzione. Scrivere dati nel posto sbagliato o usare comandi distruttivi su un dispositivo può avere conseguenze gravi.
/proc: una finestra su processi e kernel
La directory /proc è ancora più particolare.
Molti file dentro /proc non sono realmente salvati su disco. Sono creati
dinamicamente dal kernel per mostrare informazioni sul sistema.
Per esempio, dentro /proc possiamo trovare directory numeriche che
corrispondono ai processi in esecuzione. Ogni processo ha un PID, cioè un
identificativo numerico, e può avere una rappresentazione dentro /proc.
Possiamo trovare anche informazioni sulla CPU, sulla memoria, sui parametri del kernel e su altri aspetti interni del sistema.
Quindi /proc è come un pannello diagnostico.
Non è la cartella dei documenti. Non è la cartella dei programmi. È una vista dinamica del sistema mentre è in esecuzione.
Questo è un altro esempio del principio “tutto è un file”. Informazioni dinamiche che in altri contesti potremmo vedere solo attraverso strumenti grafici o API specifiche, in Linux vengono esposte anche attraverso il filesystem.
Per iniziare basta ricordare questo: /proc serve a osservare il sistema, non
a salvare documenti.
/boot: i file necessari all’avvio
La directory /boot contiene file importanti per l’avvio del sistema.
Qui possono trovarsi il kernel, file collegati al bootloader, immagini initramfs e altri componenti necessari nelle prime fasi di avvio.
Quando accendiamo il computer, il sistema passa attraverso varie fasi:
firmware, bootloader, caricamento del kernel, inizializzazione del sistema e
avvio dei servizi. /boot è collegata proprio a queste fasi iniziali.
È una directory piccola, ma molto importante.
Non è un posto in cui salvare file personali. Non è una cartella da modificare a caso. Possiamo immaginarla come la cabina di accensione del sistema.
Dove cercare cosa in Linux
A questo punto possiamo riassumere la mappa principale.
| Cosa cerchi | Dove guardare |
|---|---|
| File personali | /home |
| Configurazioni di sistema | /etc |
| Comandi essenziali | /bin |
| Programmi e librerie | /usr, /usr/bin, /usr/lib |
| Log | /var/log |
| Dati variabili | /var |
| File temporanei | /tmp |
| Dispositivi | /dev |
| Processi e informazioni del kernel | /proc |
| File di avvio | /boot |
Questa è una delle mappe più utili per chi sta imparando Linux.
Non serve sapere tutto a memoria. L’importante è capire la logica generale.
Linux non organizza i file in modo casuale. Le directory principali hanno un ruolo preciso. Quando capiamo quel ruolo, diventa molto più semplice leggere guide, seguire tutorial, capire errori e amministrare il sistema.
Cosa significa montare un disco in Linux
Un altro concetto fondamentale è il mount.
Su Windows siamo abituati a vedere dischi e partizioni come unità separate:
C:, D:, E: e così via.
In Linux il modello è diverso. Il filesystem è un unico albero che parte da
/. Quando colleghiamo o usiamo un altro disco, quel disco viene collegato a
una directory dell’albero.
Quella directory si chiama mount point.
Per esempio, una chiavetta USB può essere montata sotto:
/media/nomeutente/chiavetta
Un disco dati può essere montato in:
/mnt/dati
Una partizione separata può essere montata direttamente come:
/home
Montare un disco significa quindi collegare un filesystem a un punto dell’albero principale.
L’analogia può essere quella di una grande biblioteca. La biblioteca ha già sale, scaffali e percorsi. Quando arriva un nuovo archivio, non serve dargli per forza un edificio separato con una lettera. Lo si collega a uno scaffale preciso. Da quel momento, entrando in quel percorso, si accede al contenuto dell’archivio.
Questo spiega perché in Linux possiamo avere un’unica struttura ordinata anche se fisicamente i dati stanno su dischi diversi, partizioni diverse, dispositivi esterni o risorse di rete.
Differenza tra filesystem Linux e Windows
La differenza principale tra Linux e Windows riguarda il modo di pensare lo spazio.
In Windows spesso ragioniamo per unità:
C:
D:
E:
In Linux ragioniamo per albero:
/
Tutto parte dalla directory root /, e i vari filesystem vengono collegati a
punti specifici di questo albero.
Un’altra differenza riguarda l’organizzazione dei programmi.
Su Windows un’applicazione spesso ha una cartella principale dentro Programmi. Molti file dell’applicazione vengono messi lì.
Su Linux, invece, i file vengono distribuiti in base alla loro funzione. Gli
eseguibili possono stare in /usr/bin, le librerie in directory dedicate, le
configurazioni in /etc, i log in /var/log, i dati utente in /home.
Questo approccio può sembrare più tecnico all’inizio, ma diventa molto utile quando si amministrano sistemi, server e ambienti complessi.
Se sappiamo che i log stanno in /var/log, non dobbiamo indovinare ogni volta
dove un programma ha deciso di salvare i propri messaggi. Se sappiamo che le
configurazioni stanno spesso in /etc, abbiamo già una direzione. Se sappiamo
che i dati personali stanno in /home, sappiamo dove cercare i file degli
utenti.
Linux non è organizzato prima di tutto per “applicazione vista dall’utente”, ma per “funzione del file dentro il sistema”.
Errori comuni dei principianti
Quando si inizia a usare Linux, alcuni errori sono molto comuni.
Il primo errore è confondere / con /root. La directory / è la radice del
filesystem. La directory /root, invece, è la home dell’utente root, cioè
dell’amministratore.
Il secondo errore è pensare che /home contenga tutto il sistema. In realtà
/home contiene i dati degli utenti, non il sistema operativo.
Il terzo errore è modificare file dentro /etc senza capire cosa fanno. Molte
guide mostrano modifiche a file di configurazione, ma prima di intervenire è
sempre bene capire il ruolo del file e fare attenzione.
Il quarto errore è usare /tmp come archivio permanente. /tmp è pensata per
file temporanei, non per conservare dati importanti.
Il quinto errore è cancellare log o file di sistema pensando di fare pulizia. Lo spazio disco va gestito con criterio, non eliminando directory a caso.
Il sesto errore è trattare /dev/sda, /dev/nvme0n1 o altri file in /dev
come file normali. In realtà rappresentano dispositivi e operazioni sbagliate
possono essere pericolose.
Il settimo errore è non capire il concetto di mount. Una chiavetta, un disco o una partizione non appaiono come nuove lettere, ma vengono montati in un punto dell’albero.
Questi errori sono normali. Fanno parte dell’apprendimento. Ma appena capiamo la logica generale del filesystem, diventano molto più facili da evitare.
Perché capire il filesystem rende Linux più semplice
Il filesystem Linux è una delle chiavi per capire il sistema operativo.
Molte difficoltà iniziali nascono dal fatto che si vedono directory strane
senza sapere che ruolo hanno. /etc, /var, /usr, /dev e /proc possono
sembrare nomi casuali, ma non lo sono.
Quando capiamo la funzione di queste directory, Linux diventa molto più leggibile.
Se un servizio non funziona, possiamo pensare ai log in /var/log.
Se vogliamo capire come è configurato qualcosa, possiamo pensare a /etc.
Se cerchiamo file personali, pensiamo a /home.
Se vediamo un disco o una partizione, sappiamo che potrebbe essere rappresentato
in /dev.
Se vogliamo osservare informazioni dinamiche sul sistema, sappiamo che /proc
può mostrarci una vista interna.
Questa mappa mentale è più importante della memorizzazione meccanica. Non serve conoscere ogni directory esistente. Serve sapere come ragiona Linux.
Riepilogo: filesystem Linux spiegato semplice
Il filesystem Linux è il modo in cui il sistema organizza file, directory, programmi, configurazioni, dispositivi e informazioni interne.
La radice di tutto è /, la directory root. Da lì parte un unico albero.
In Linux si dice che “tutto è un file” perché molte risorse vengono rappresentate attraverso un’interfaccia simile a quella dei file: documenti, directory, dispositivi, terminali, processi e informazioni del kernel.
/home contiene i dati degli utenti.
/etc contiene configurazioni di sistema.
/bin e /usr sono collegati a programmi, comandi, librerie e componenti
condivisi.
/var contiene dati variabili, inclusi molti log.
/tmp contiene file temporanei.
/dev contiene file speciali collegati ai dispositivi.
/proc mostra informazioni dinamiche su processi e kernel.
/boot contiene file necessari all’avvio del sistema.
Montare un disco significa collegare un filesystem a un punto dell’albero principale, chiamato mount point.
La cosa più importante da ricordare è questa: Linux non mette i file a caso. Li organizza per funzione.
Quando capiamo questa logica, Linux smette di sembrare un insieme di cartelle strane e diventa una struttura ordinata.
Prossimo passo: capire i permessi Linux
Dopo aver capito dove stanno i file, il passo successivo è capire chi può usarli.
Nel prossimo episodio della serie parleremo dei permessi Linux. Vedremo il
modello multiutente, la differenza tra owner, group e others, i permessi di
lettura, scrittura ed esecuzione, indicati con r, w e x, e il significato
di stringhe come:
-rwxr-xr--
Il filesystem ci dice dove si trovano i file. I permessi ci dicono chi può leggerli, modificarli o eseguirli.
Per capire davvero Linux, questi due concetti devono andare insieme.
Ti interessano tutorial su programmazione, sviluppo web, Linux, sicurezza, sistemi operativi e software open source? Iscriviti al canale YouTube:
https://www.youtube.com/@scrivocodice?sub_confirmation=1
Puoi seguire i nostri corsi su Udemy:
https://www.udemy.com/user/scrivocodice/
Seguici anche qui: